Open-Source AI Feedback Alignment
RLAIF-V builds a fully open feedback pipeline so multimodal alignment no longer depends on proprietary annotators.
Project Page
arXiv 2024
RLAIF-V builds a fully open feedback pipeline so multimodal alignment no longer depends on proprietary annotators.
The framework combines preference optimization with self-feedback guidance to improve trustworthiness during both learning and decoding.
The paper reports large reductions in object hallucination while maintaining or improving helpfulness on general multimodal benchmarks.
RLAIF-V asks whether multimodal alignment can be done effectively without relying on proprietary supervision or large-scale human preference annotation. The paper proposes a fully open-source feedback learning framework for improving the trustworthiness of MLLMs, with a particular focus on reducing hallucination and making the alignment pipeline more reproducible.
The project combines preference learning with inference-time self-feedback guidance. That makes it more than a standard fine-tuning recipe: it is both a data-construction pipeline and a model-improvement framework for training-time and decoding-time trustworthiness.
RLAIF-V builds high-quality feedback pairs using open-source MLLMs, a deconfounded data construction strategy, and a divide-and-conquer evaluation process that scores atomic claims more precisely. During inference, the aligned model can further improve itself with self-feedback guidance, which acts as an inference-time scaling mechanism for trustworthiness. The project also uses a reference-based review setting with a reported 96% human agreement on the dev split, which helps support the reliability of the automatic evaluation process.
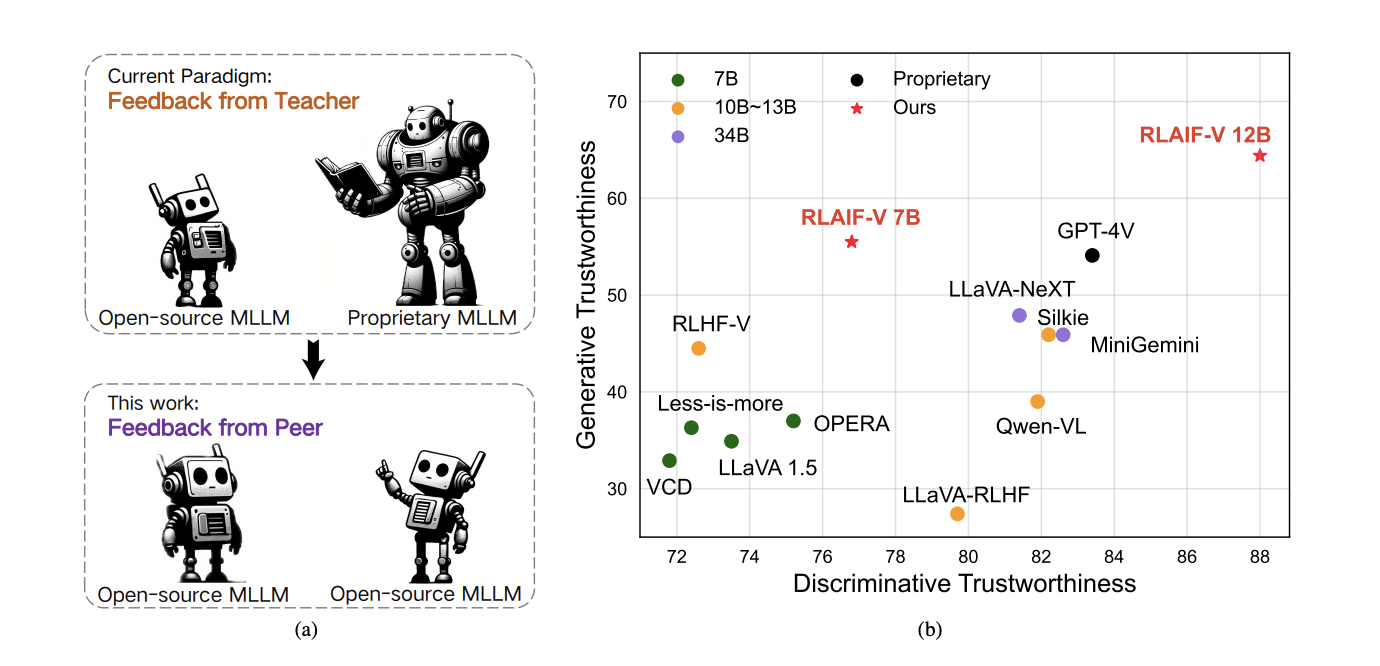
RLAIF-V aligns MLLMs with open-source AI feedback and extends that feedback signal into inference-time self-improvement.
RLAIF-V matters because it demonstrates that open-source feedback can be a serious alignment signal for multimodal systems. That lowers the barrier for research teams who want to work on trustworthy MLLMs without depending on inaccessible proprietary annotation loops.
It also suggests a broader lesson: trustworthiness should not be treated as a purely training-time property. Feedback can be used to shape both the data and the decoding process, which makes alignment more flexible and potentially more effective in practice.
@article{yu2024rlaifv,
title={RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness},
author={Yu, Tianyu and Zhang, Haoye and Yao, Yuan and Dang, Yunkai and Chen, Da and Lu, Xiaoman and Cui, Ganqu and He, Taiwen and Liu, Zhiyuan and Chua, Tat-Seng and Sun, Maosong},
journal={arXiv preprint arXiv:2405.17220},
year={2024}
}