Language-Guided Few-Shot Learning
FILM uses pretrained language-model semantics as a core signal for few-shot classification instead of a light auxiliary prior.
Project Page
arXiv 2023
FILM uses pretrained language-model semantics as a core signal for few-shot classification instead of a light auxiliary prior.
A learned metric and bi-level optimization improve how visual evidence and textual class semantics are compared across episodes.
The method reports clear improvements on miniImageNet, tieredImageNet, CIFAR-FS, and CUB in both 1-shot and 5-shot settings.
FILM asks how few-shot image classification can benefit more substantially from pre-trained language models. Earlier methods often use semantic information from class names, but only as a lightweight auxiliary cue added to otherwise standard few-shot pipelines. FILM instead treats language-derived semantic structure as a central component of the classifier design.
The paper proposes a contrastive few-shot learning framework that aligns visual features and language-model embeddings more carefully. The goal is better transferability to novel classes, especially when only one or a few labeled examples are available.
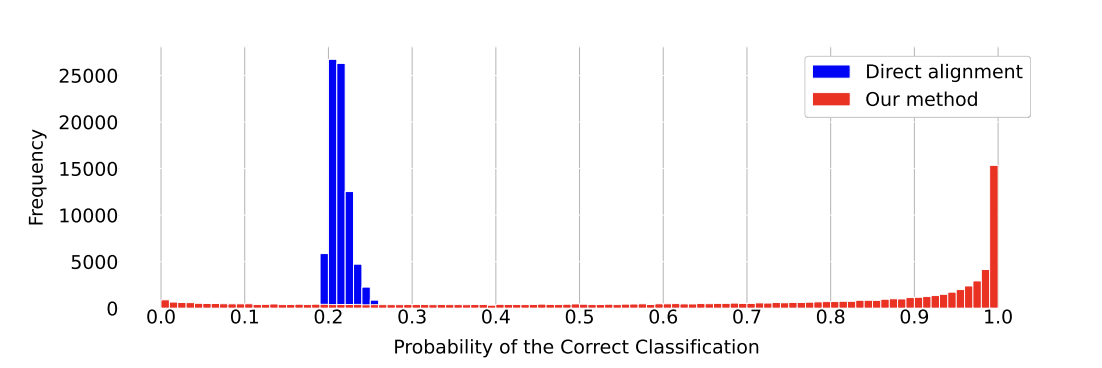
FILM integrates pre-trained language-model semantics directly into the few-shot matching process.
Language-Guided Few-Shot Learning: FILM treats class semantics from pretrained language models as a core transfer signal rather than a weak auxiliary hint.
Adaptive Visual-Text Metric: the model learns a comparison function that goes beyond cosine similarity so support and query images can be matched with textual semantics more flexibly.
Task-Adaptive Meta Optimization: MAML-style bi-level training allows the metric to adapt to each few-shot episode instead of staying fixed across tasks.
Benchmark Gain: FILM improves miniImageNet by +2.42% and +4.41%, and tieredImageNet by +3.88% and +4.41% in 1-shot and 5-shot settings.
Paper Resource: the full method and experiments are available on arXiv.
This is not simply a language-augmented prototype classifier. The paper is really about building a better transfer metric between vision and language so that few-shot recognition can exploit semantic priors without collapsing into brittle label-name matching.
FILM introduces a textual branch that is specifically designed to align with visual representations extracted from few-shot episodes. A learned metric module then generalizes cosine similarity so that the model can compare visual and textual information more flexibly. To improve adaptation across tasks, the method is trained with MAML-style bi-level optimization, allowing the metric to adjust to new few-shot episodes rather than staying fixed.
FILM is valuable because it does not treat language as an afterthought. It shows that pre-trained language models can serve as a structured semantic prior for low-data visual recognition, especially when the alignment mechanism is designed carefully.
The larger takeaway is that few-shot recognition can benefit from foundation-model semantics, but only if the model learns how to compare visual and textual information in a task-adaptive way. FILM is an early and still useful example of that design principle.
@article{jiang2023film,
title={FILM: How can Few-Shot Image Classification Benefit from Pre-Trained Language Models?},
author={Jiang, Zihao and Dang, Yunkai and Pang, Dong and Zhang, Huishuai and Huang, Weiran},
journal={arXiv preprint arXiv:2307.04114},
year={2023}
}