Query-Guided Token Compression
UHR-BAT allocates the visual token budget according to the current instruction so that small but decisive evidence is preserved.
Project Page
ICML 2026
UHR-BAT allocates the visual token budget according to the current instruction so that small but decisive evidence is preserved.
The framework keeps informative regional tokens and merges redundant ones, reducing cost without destroying spatial structure.
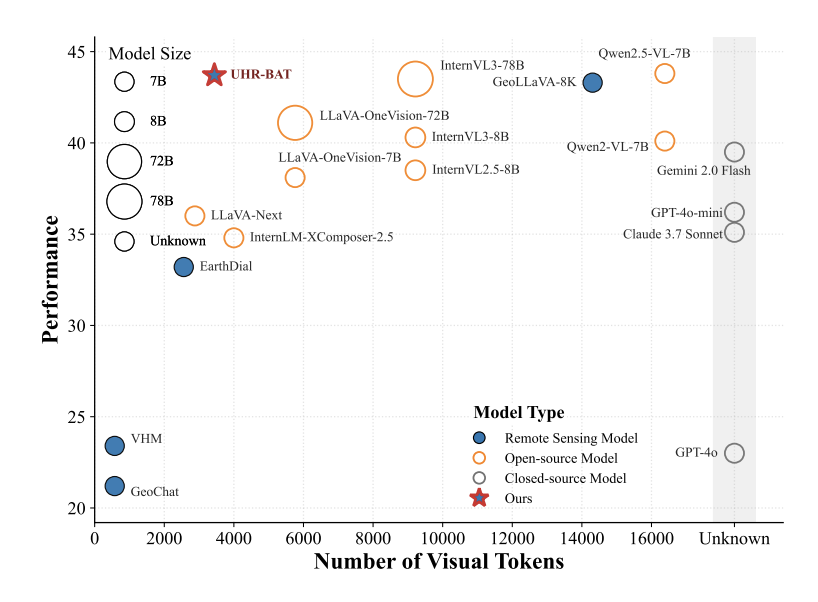
The model reports 44.0 weighted average on XLRS-Bench and strong gains on MMERealworld-RS and RSHR-Bench.
Ultra-high-resolution (UHR) remote sensing imagery couples kilometer-scale context with query-critical evidence that may occupy only a few pixels. Such vast spatial scale leads to a quadratic explosion of visual tokens and hinders the extraction of information from small objects. Previous works utilize direct downsampling, dense tiling, or global top-k pruning, which either compromise query-critical image details or incur unpredictable compute. In this paper, we propose UHR-BAT, a query-guided and region-faithful token compression framework to efficiently select visual tokens under a strict context budget.e Specifically, we leverage text-guided, multi-scale importance estimation for visual tokens, effectively tackling the challenge of achieving precise yet low-cost feature extraction. Furthermore, by introducing region-wise preserve and merge strategies, we mitigate visual token redundancy, further driving down the computational budget. Experimental results show that UHR-BAT achieves state-of-the-art performance across various benchmarks. Code will be available at this https URL.
UHR-BAT keeps query-relevant evidence while aggressively compressing redundant visual tokens in ultra-high-resolution scenes.
UHR-BAT Framework: We propose UHR-BAT, a token compression framework designed for ultra-high-resolution remote-sensing MLLMs under strict context budgets.
Query-Guided Multi-Scale Input: We propose a query-guided, multi-scale input mechanism to integrate text-derived global priors and capture both holistic context and fine-grained details.
Region-Wise Preserve and Merge: We propose region-wise preserve and merge strategies to preserve salient local evidence and aggregate redundant background into compact representatives.
Empirical Results: Experiments across standard benchmarks confirm that UHR-BAT establishes a new state of the art for efficient UHR understanding, outperforming existing methods under strict token budgets.
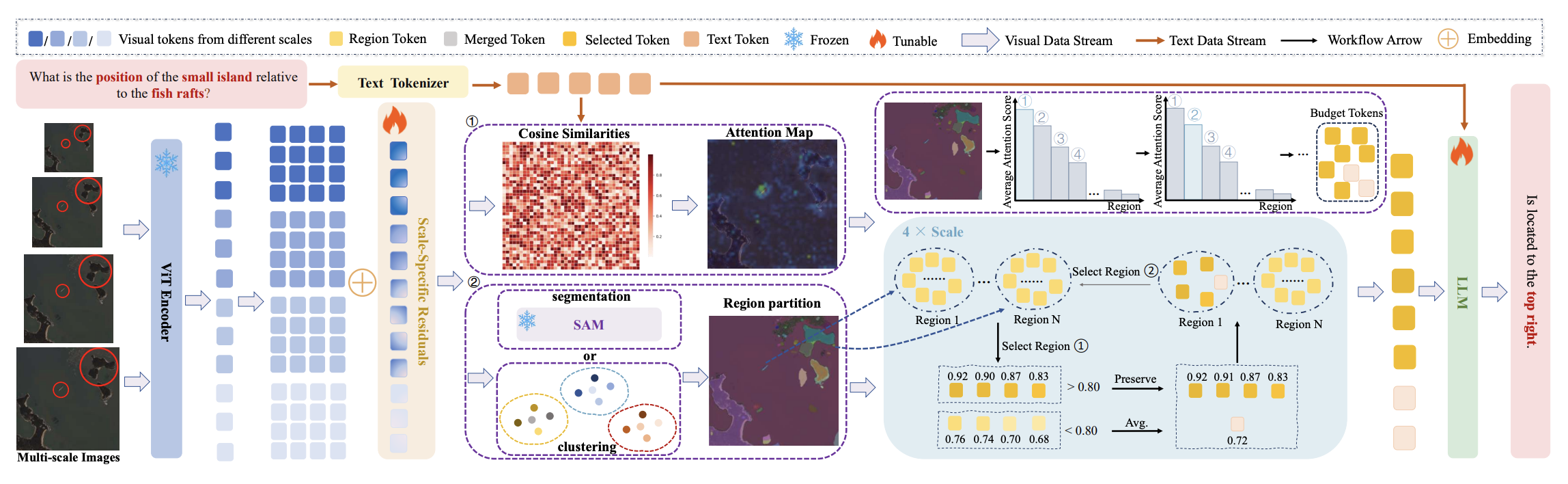
Method Overview. We encode a high-resolution remote sensing image at multiple scales using a frozen ViT, apply scale-specific positional embeddings to distinguish visual tokens across scales, and obtain an anchor-scale query-to-vision attention map from the MLLM interface. A region partition, induced by SAM or feature-plus-coordinate clustering, enables region-wise preserve-and-merge, while remaining tokens are merged via average pooling to retain coarse context. A final top-k step enforces the per-scale token budget before the processed sequence is fed into the LLM for answer generation.
UHR-BAT encodes ultra-high-resolution remote-sensing images at multiple scales, uses query-to-vision attention to identify the anchor-scale evidence relevant to the current instruction, and then performs region-wise preserve-and-merge so that salient local structures are retained while redundant background tokens are compressed into compact representatives. The final top-k selection step guarantees that each scale respects the preset token budget.
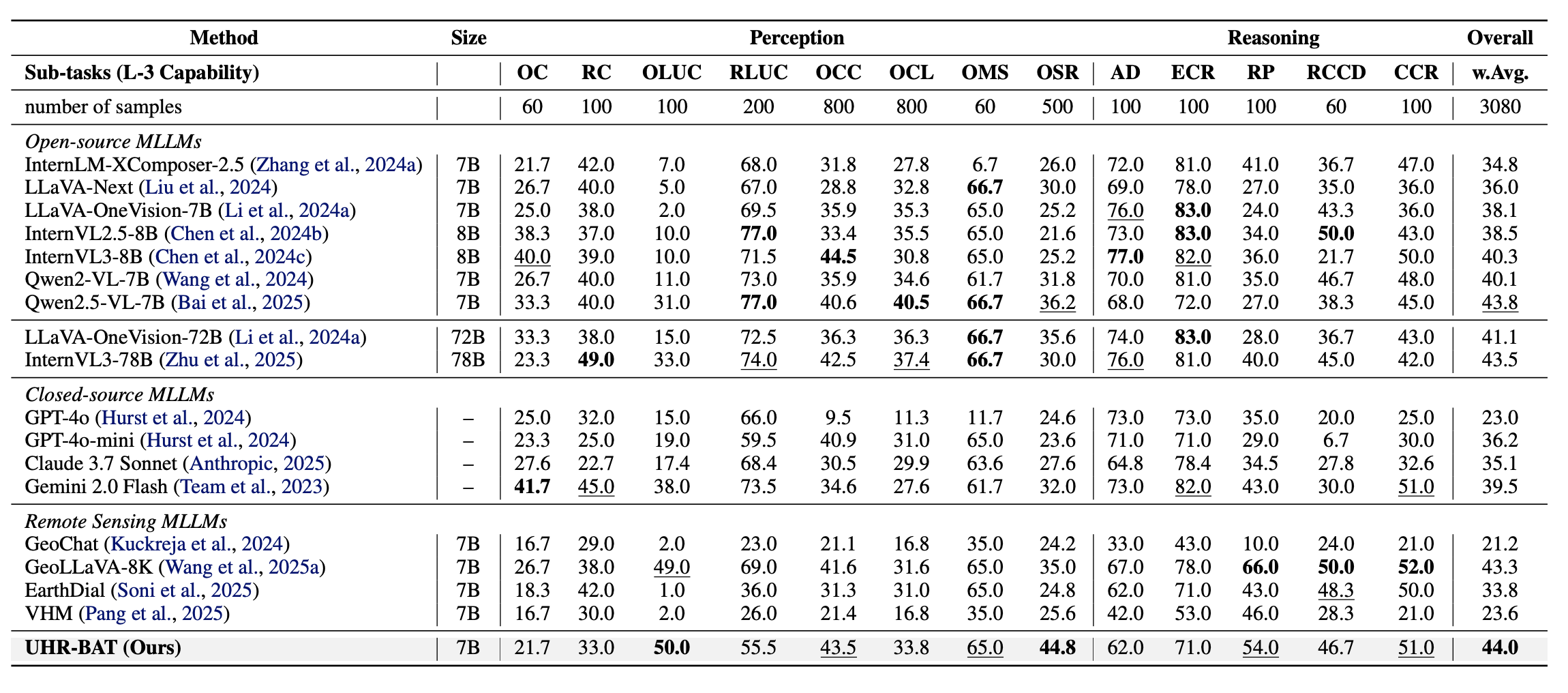
XLRS-Bench Results. This table summarizes perception and reasoning sub-task performance under strict token budgets and shows that UHR-BAT achieves a new state of the art with 44.0 weighted average accuracy.
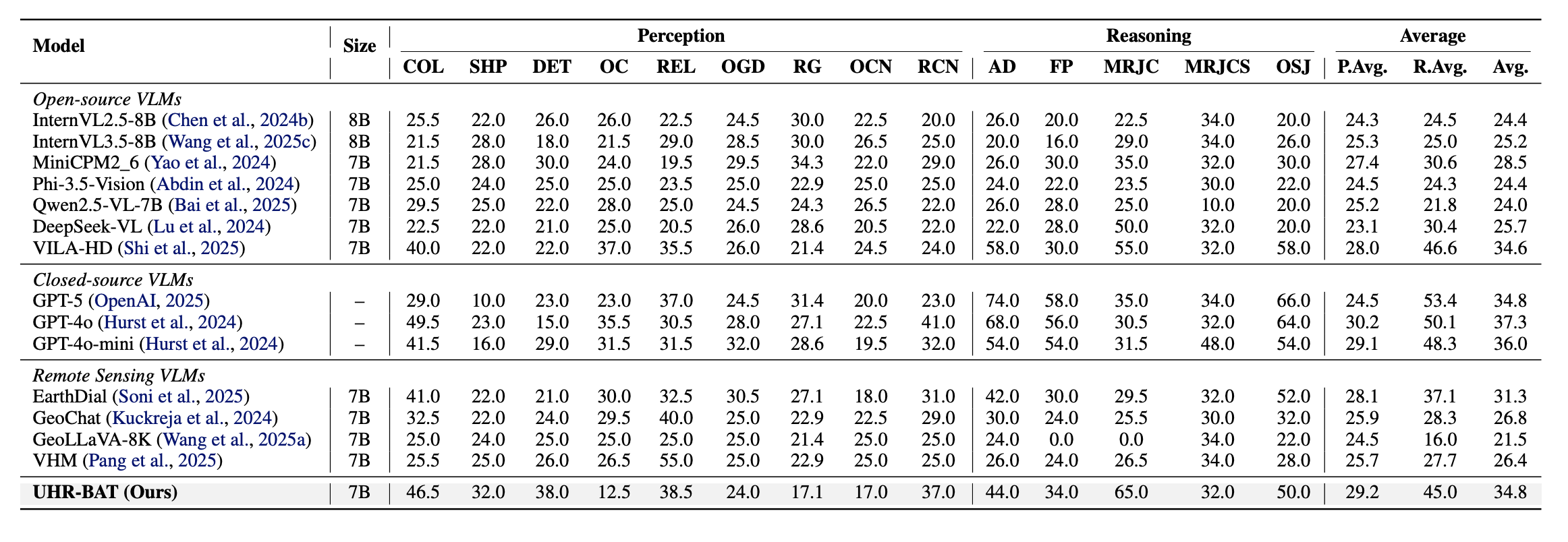
RSHR-Bench Results. The reported Perception and Reasoning scores show that UHR-BAT remains strong across diverse remote-sensing question types while operating under a constrained visual token budget.

Attention Maps. We display original images and enlarged views alongside their corresponding attention maps. The heatmaps show that the model focuses on semantically relevant regions, such as specific vehicles or infrastructure aligned with the textual query, while assigning lower importance to the background.
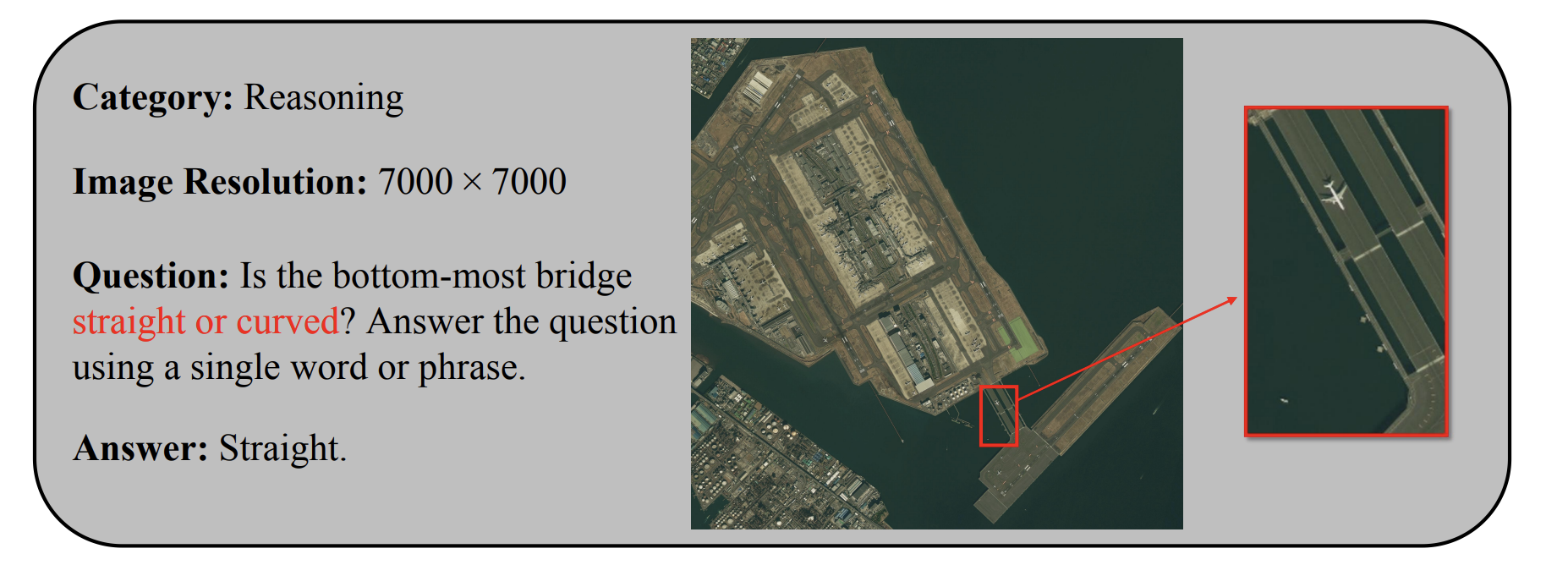
Response Example A. This sample illustrates the versatility of our method in handling spatial reasoning and fine-grained attribute recognition on small objects in ultra-high-resolution scenes.
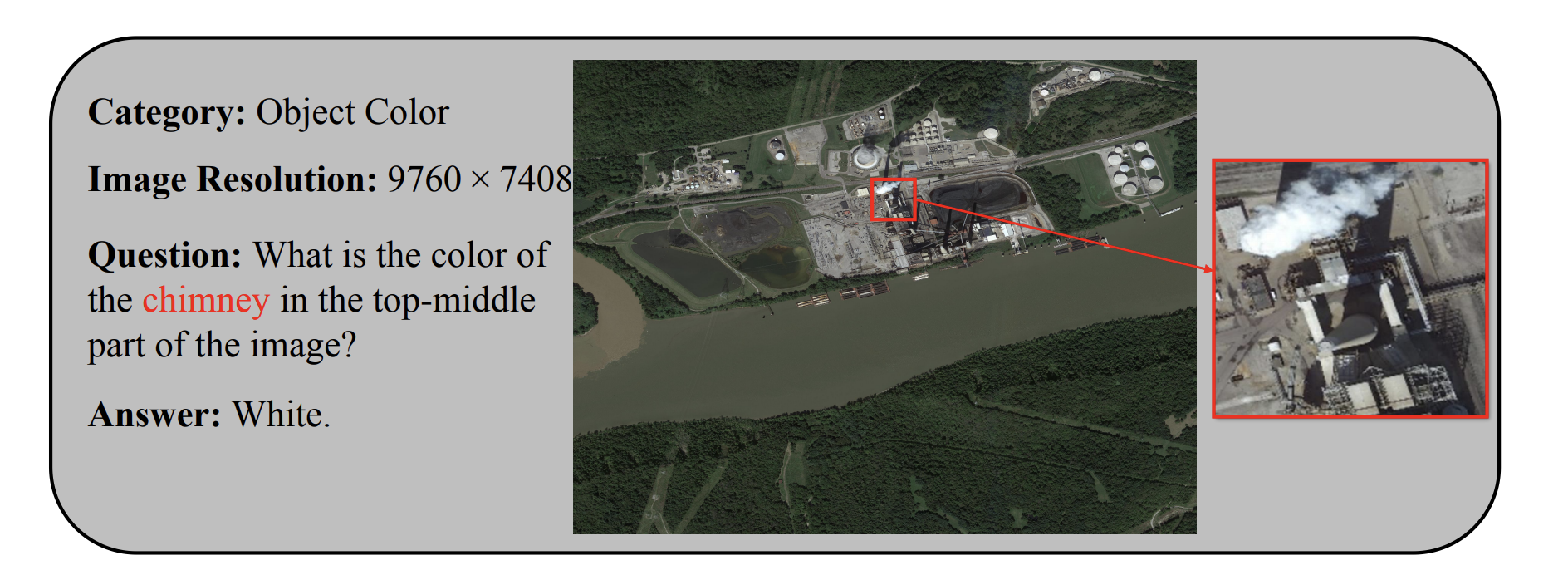
Response Example B. This sample further shows that UHR-BAT can answer query-specific reasoning questions while preserving the small visual evidence required for precise recognition.
The main takeaway is that token compression for remote sensing cannot be treated as a purely generic speed trick. The model has to remain sensitive to tiny, sparse, and spatially significant evidence. UHR-BAT shows that budget-aware compression can still improve accuracy when the compression rule is aligned with query semantics and region structure.
For practical Earth observation systems, this matters because the deployment bottleneck is usually not just model quality, but quality under strict memory and latency limits. UHR-BAT is therefore useful not only as a better benchmark result, but also as a stronger recipe for building scalable remote sensing MLLMs.
@article{dang2026uhr,
title={UHR-BAT: Budget-Aware Token Compression Vision-Language model for Ultra-High-Resolution Remote Sensing},
author={Dang, Yunkai and Dai, Minxin and Yang, Yuekun and Li, Zhangnan and Li, Wenbin and Miao, Feng and Gao, Yang},
journal={arXiv preprint arXiv:2604.13565},
year={2026}
}