Dual-Channel Confidence Evaluation
The paper jointly models instinctive token probabilities and reflective verbal self-assessment instead of relying on a single confidence source.
Project Page
arXiv 2026
The paper jointly models instinctive token probabilities and reflective verbal self-assessment instead of relying on a single confidence source.
Confidence signals are extracted from open-source and proprietary MLLMs across diverse multimodal reasoning benchmarks and prompt strategies.
A monotone fusion head and order-preserving mean alignment produce better calibrated reliability estimates.
Multimodal Large Models can expose confidence through two different channels. The first is instinct: the probability distribution over answer tokens. The second is reflection: the model’s explicit verbalized estimate of how confident it is. These two signals are often treated separately, even though both are available during multimodal inference and both can fail in different ways. In this paper, we study how to unify token confidence and verbalized confidence for better MLLM reliability estimation. Instead of relying on self-consistency aggregation, prompt-only strategies, or a single confidence source, the method extracts both channels and combines them with monotone confidence fusion so that the final score is better aligned with actual correctness.
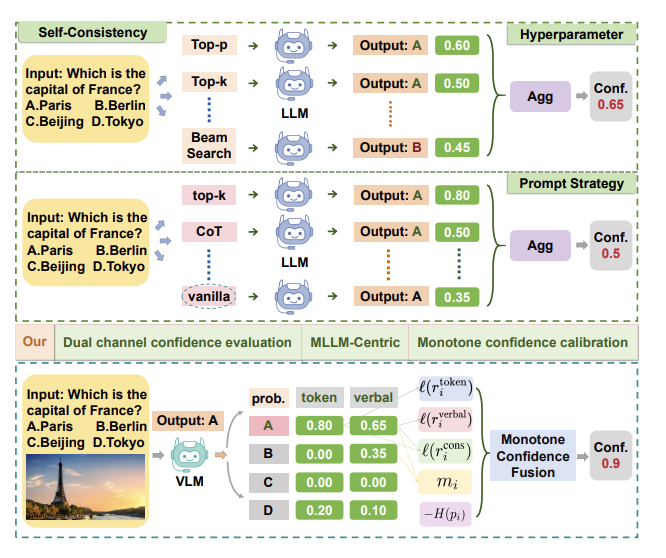
Motivation. Prior confidence estimation strategies are sensitive to sampling, aggregation, and prompting choices. The proposed framework uses both token-level probabilities and verbalized self-assessment signals, then calibrates them through monotone fusion.
Dual-Channel Confidence Evaluation: the framework evaluates both token-level probability confidence and verbalized self-assessment confidence for answer options.
MLLM-Centric Reliability Modeling: the analysis focuses on real MLLM behavior across benchmarks, prompt strategies, and model families rather than treating confidence as a generic text-only calibration problem.
Monotone Confidence Calibration: the fusion module combines complementary confidence cues while preserving reliability ordering and correcting distribution shifts.
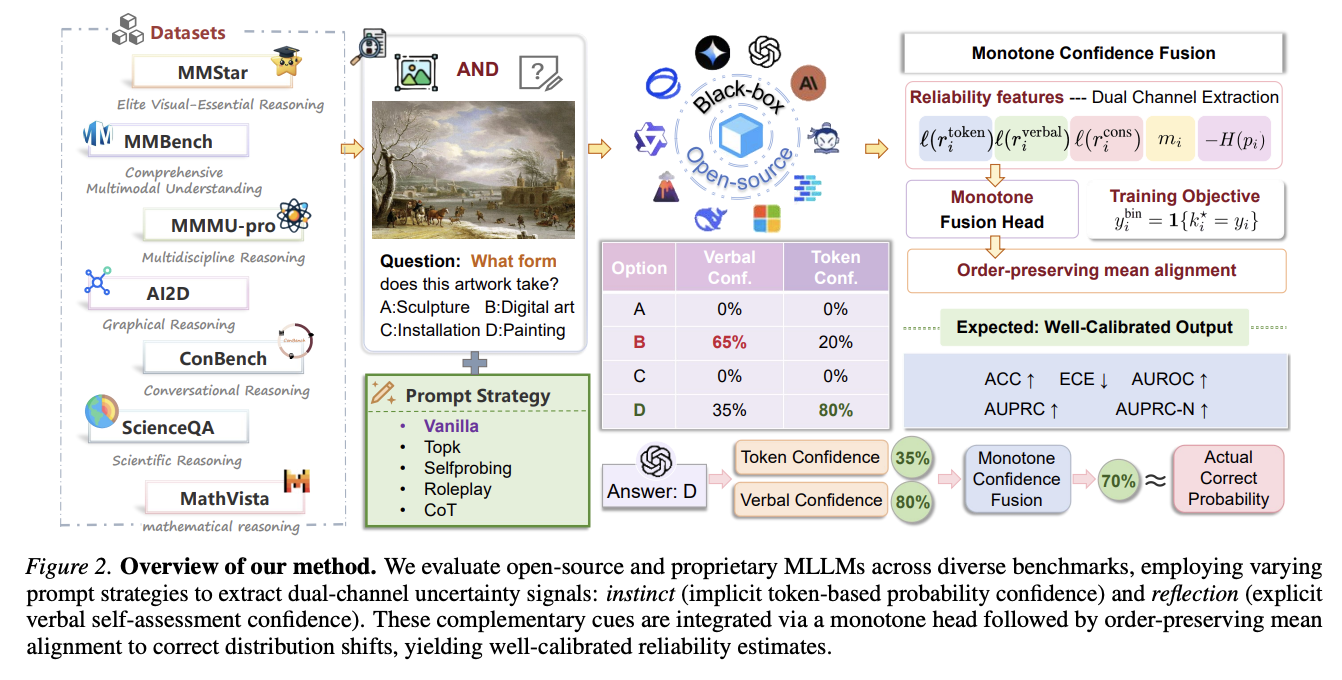
Method Overview. The framework evaluates MLLMs across diverse benchmarks and prompt strategies, extracts token and verbal confidence for answer options, and feeds reliability features into a monotone fusion head followed by order-preserving mean alignment.
The method evaluates open-source and proprietary MLLMs on multimodal reasoning benchmarks such as MMBench, MMStar, MMMU-Pro, AI2D, ConBench, and ScienceQA. For each question, it extracts confidence signals from both the output token distribution and the model’s verbal confidence response under different prompt strategies, including vanilla prompting, top-k prompting, self-probing, roleplay, and chain-of-thought variants.
The final calibrated score is produced from reliability features including token confidence, verbal confidence, consistency-related cues, answer margins, and distribution entropy. A monotone fusion head preserves the intuition that stronger reliability evidence should not decrease the final confidence, while order-preserving mean alignment corrects distribution shifts across models and datasets.
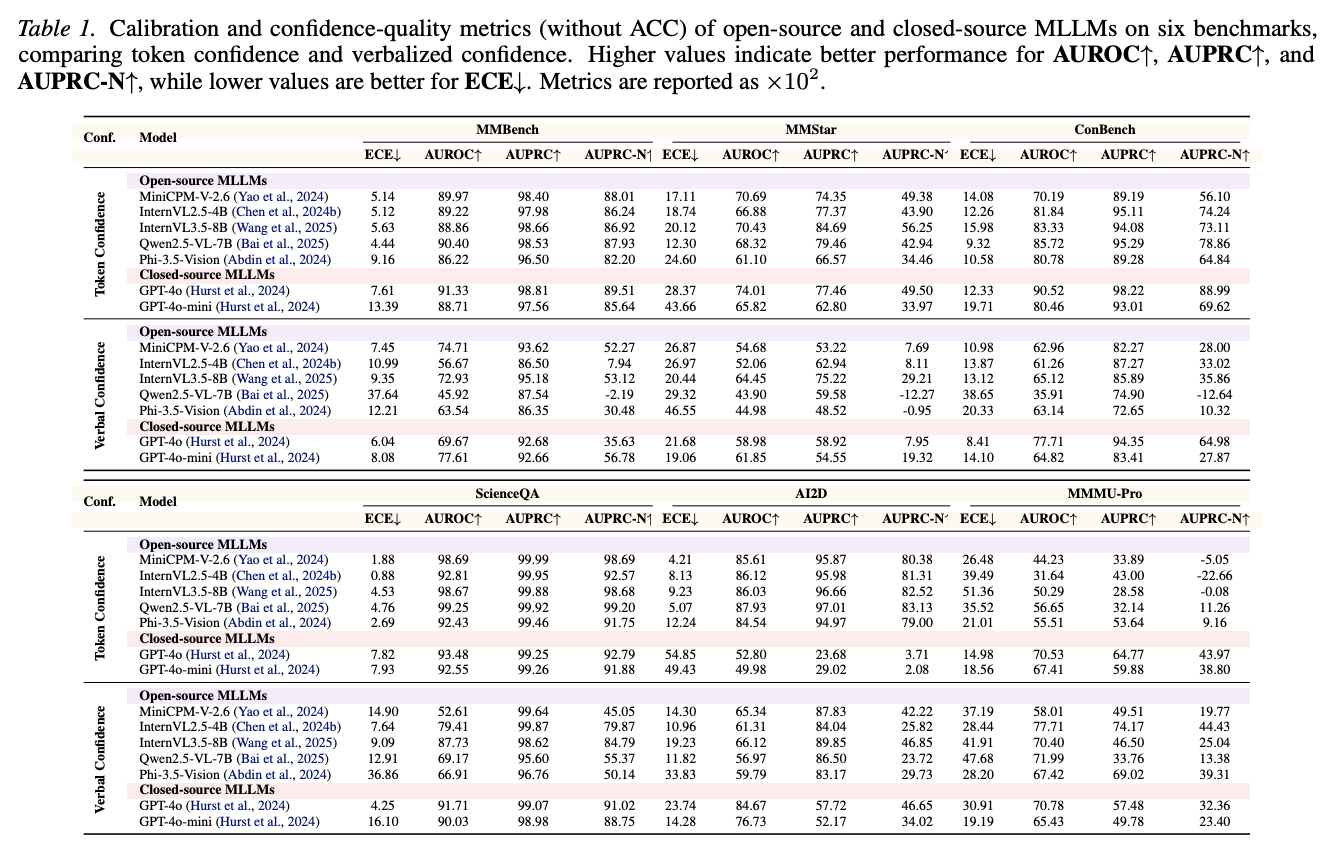
Token vs. Verbal Confidence. The experiments compare calibration and confidence-quality metrics, including ECE, AUROC, AUPRC, and AUPRC-N, across open-source and closed-source MLLMs.
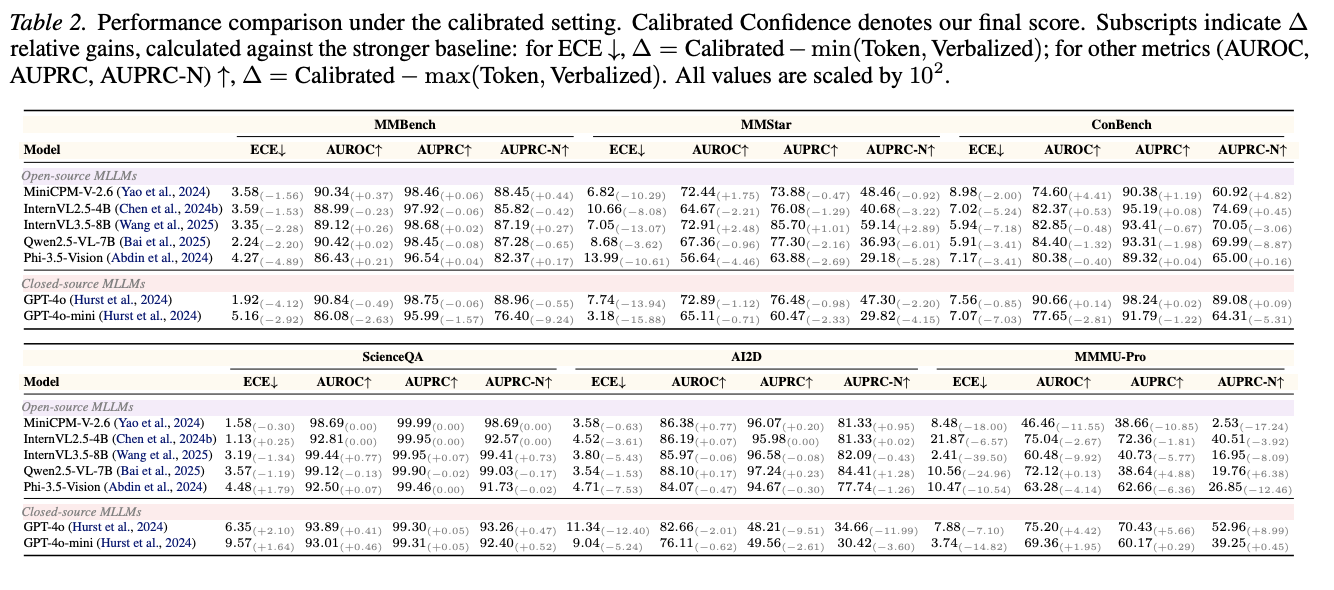
Calibrated Confidence. The final calibrated score is compared against the stronger single-channel baseline for each setting, showing how dual-channel fusion improves reliability estimation.

Verbal-Internal Disconnect. The token distribution can favor the correct answer even when verbalized confidence assigns high confidence to an incorrect option.

Under-Confident Correct Prediction. The model may answer correctly with strong token confidence while its verbalized confidence remains hesitant, illustrating why a single confidence channel is insufficient.
Confidence is useful only when it predicts whether a model is actually right. This project makes that problem concrete for multimodal systems by separating what the model’s token distribution says from what the model verbally claims about its own certainty.
The practical value is that downstream systems can use calibrated confidence as a more reliable trigger for abstention, human review, selective prediction, or model routing. By unifying instinct and reflection, the method gives a more robust view of MLLM reliability than either signal alone.
@article{dang2026instinct,
title={Instinct vs. Reflection: Unifying Token and Verbalized Confidence in Multimodal Large Models},
author={Dang, Yunkai and Jiang, Yifan and Jiang, Yizhu and Chen, Anqi and Li, Wenbin and Gao, Yang},
journal={arXiv preprint arXiv:2604.17274},
year={2026}
}