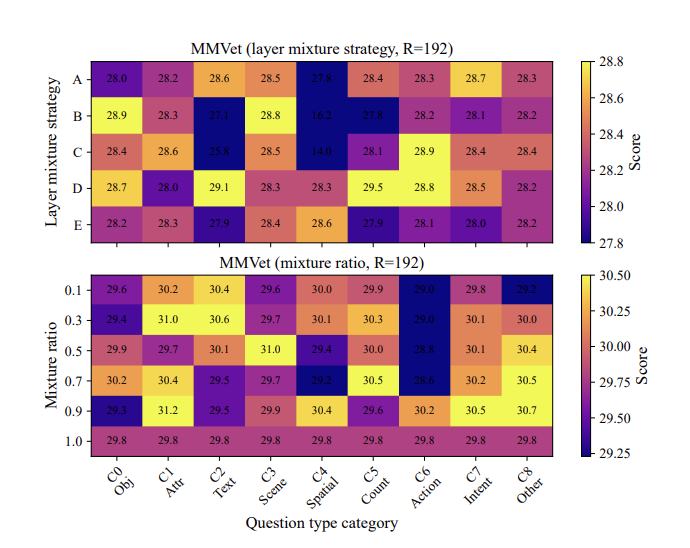
Class-Adaptive Layer Fusion
CLASP fuses multi-layer vision features according to the instruction category instead of relying on a fixed single-layer token representation.
Project Page
arXiv 2026
CLASP fuses multi-layer vision features according to the instruction category instead of relying on a fixed single-layer token representation.
The pruning budget is split between relevance-preserving pivot tokens and coverage-preserving completion tokens for more robust compression.
Under very aggressive compression, CLASP still preserves 94.7% of the original performance and remains strong across multiple MLLM backbones.
Multimodal Large Language Models (MLLMs) often serialize images into long patch-token sequences, creating heavy memory and latency costs during inference. Existing token reduction methods usually rely on single-layer ViT features and static pruning rules, which can be brittle when different instructions require different evidence, such as OCR details, object attributes, counting targets, spatial relations, or scene-level context. In this paper, we propose CLASP, a plug-and-play token reduction framework that combines class-adaptive layer fusion with class-adaptive dual-stage pruning.
The core idea is that visual token pruning should be conditioned on the semantic class of the instruction. CLASP first routes the prompt to a question category, then uses that category to choose how vision-layer features are fused and how the token budget is split between relevance and coverage. This turns token reduction from a fixed heuristic into a prompt-conditioned decision process.
Performance Under Pruning. Across eight evaluation suites, CLASP degrades more slowly than representative pruning baselines and stays closer to the unpruned upper bound, especially under aggressive pruning ratios.
Visual Token Redundancy: CLASP targets the quadratic attention cost and latency overhead caused by long visual token sequences in MLLMs.
Class-Adaptive Layer Fusion: The framework fuses multi-layer ViT features using category-specific weights instead of depending on a fixed single-layer representation.
Dual-Stage Pruning: The pruning budget is dynamically split between attention-salient pivot tokens for relevance and redundancy-aware completion tokens for coverage.
Plug-and-Play Efficiency: CLASP requires no retraining and can be integrated into multiple MLLM backbones for image and video inference.
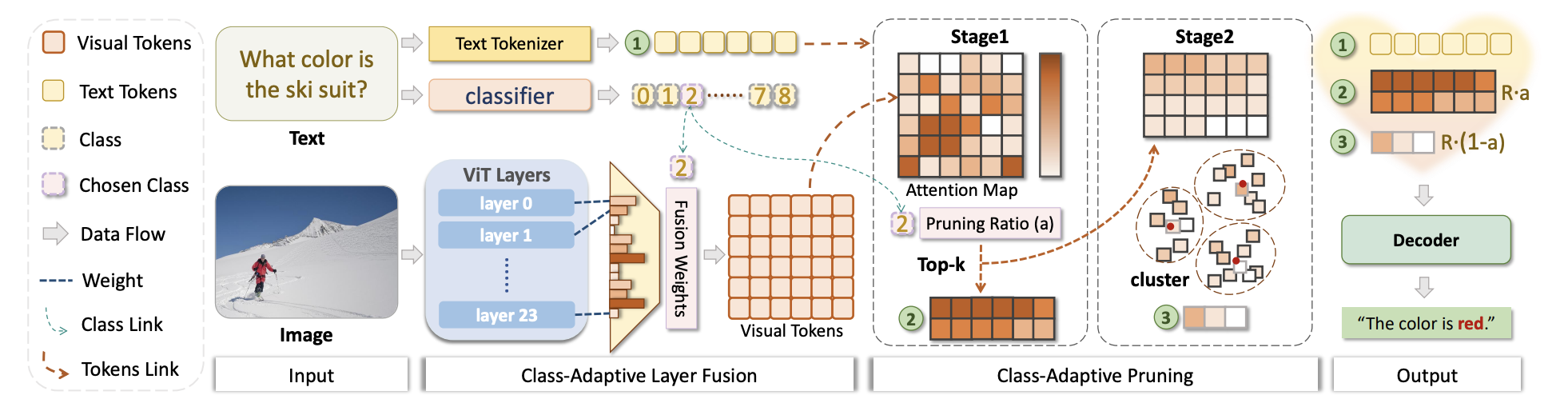
Method Overview. CLASP uses a prompt-to-class router to condition visual processing on textual intent. It first performs class-adaptive layer fusion, aggregating ViT features from multiple layers with class-specific mixture weights. It then applies class-adaptive pruning, splitting the retained token budget between attention-based selection and similarity-based clustering.
Given a prompt and an input image, CLASP aims to keep a target visual token budget R while preserving instruction-critical content and broad visual coverage. A lightweight text router maps the prompt to a category. The category then controls two decisions: the layer-mixture weights used to form the visual representation and the split ratio used during pruning.
The first pruning stage keeps attention-salient pivot tokens, which protect the most query-relevant visual evidence. The second stage uses redundancy-aware clustering to add completion tokens that are weakly covered by the pivot set, improving scene coverage without wasting budget on near-duplicate patches. In practice, the paper applies this as a progressive pruning schedule at decoder layers 2, 6, and 15.
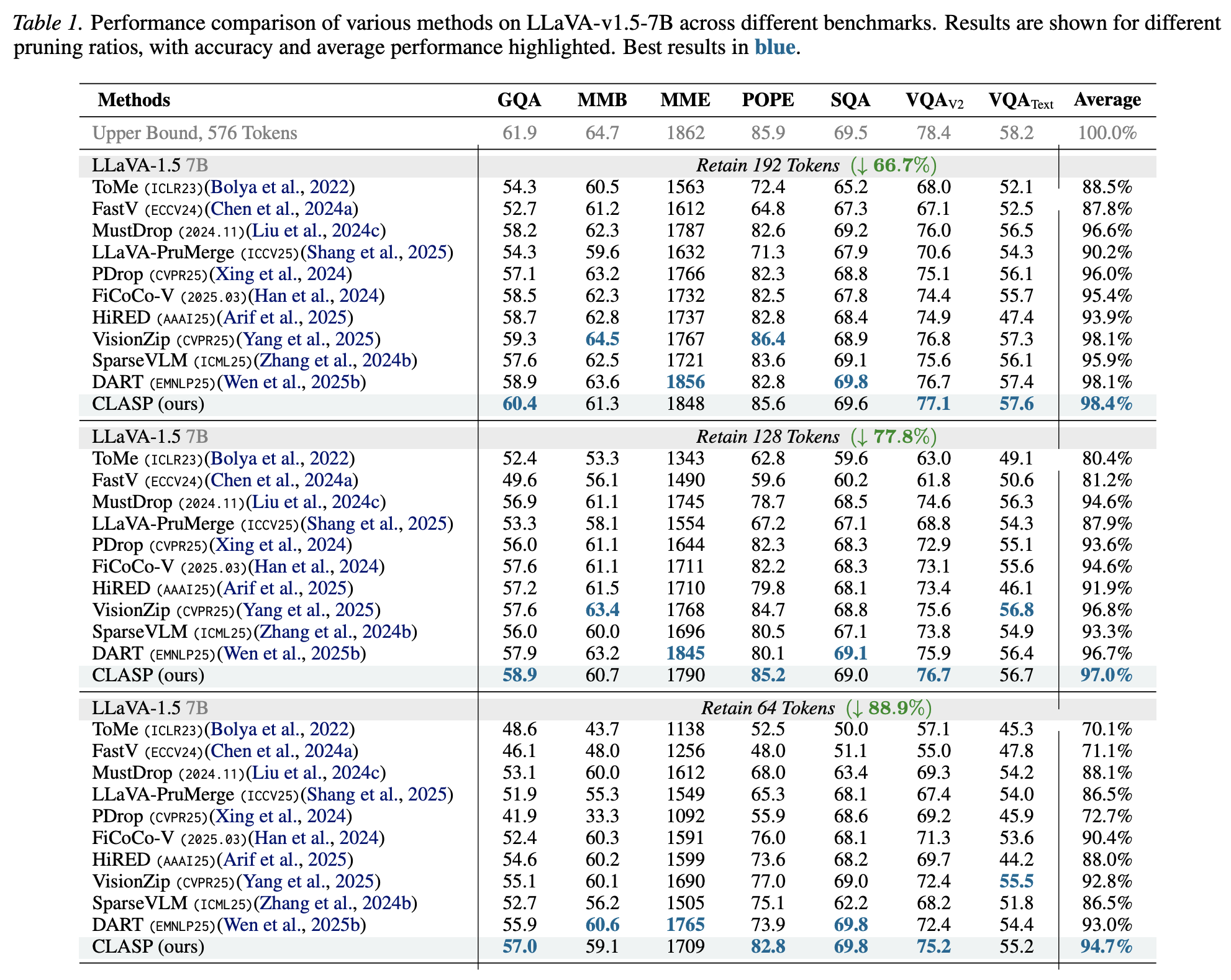
LLaVA-v1.5-7B Results. CLASP reports the best normalized average at all three tested retained-token budgets: 98.4% at 192 tokens, 97.0% at 128 tokens, and 94.7% at 64 tokens.
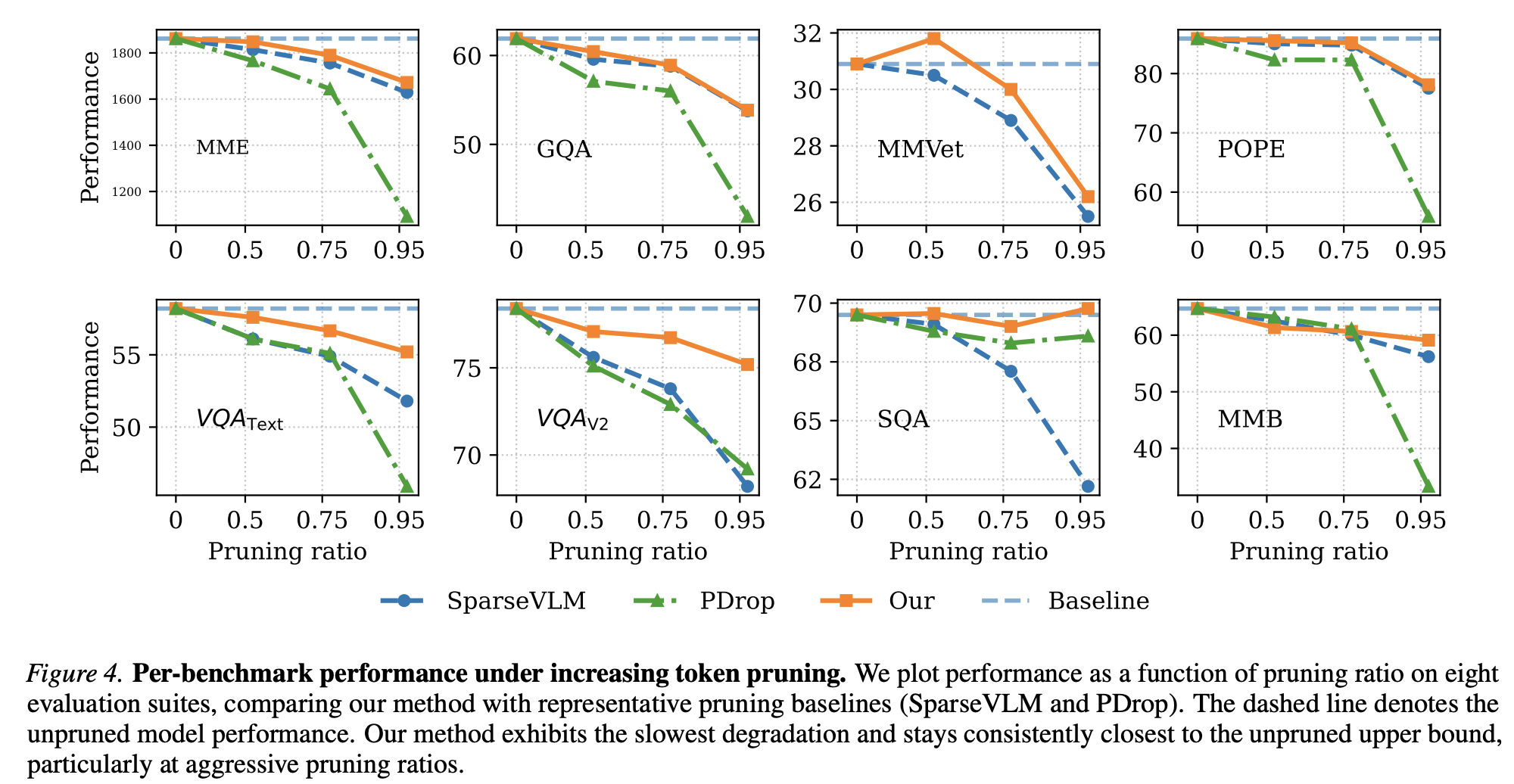
Per-Benchmark Curves. Compared with SparseVLM and PDrop, CLASP maintains stronger results across MME, GQA, MMVet, POPE, TextVQA, VQAv2, SQA, and MMB as pruning becomes more aggressive.

Token-Retention Maps. The visualization compares SparseVLM and CLASP across progressive pruning layers. CLASP retains more task-relevant regions while using attention-selected tokens for relevance and similarity-selected tokens for contextual coverage.
The efficiency study on POPE further shows that CLASP reduces inference cost while preserving accuracy. With 192 retained tokens, CLASP reaches 99.6% accuracy retention and a 1.5x time speedup. With 58 retained tokens, it keeps 95.4% accuracy retention and reaches a 2.1x time speedup.
CLASP is useful because it frames efficiency as a conditional modeling problem rather than a hard-coded compression rule. That is a better fit for real multimodal systems, where the visual evidence needed for OCR, counting, grounding, spatial reasoning, and scene understanding can be very different.
The practical implication is that token pruning does not have to be a crude tradeoff between speed and quality. By conditioning both feature fusion and pruning on the instruction category, CLASP can remove most visual tokens while preserving the evidence needed for robust multimodal inference.
@article{dang2026clasp,
title={CLASP: Class-Adaptive Layer Fusion and Dual-Stage Pruning for Multimodal Large Language Models},
author={Dang, Yunkai and Jiang, Yizhu and Jiang, Yifan and Fan, Qi and Shi, Yinghuan and Li, Wenbin and Gao, Yang},
journal={arXiv preprint arXiv:2604.12767},
year={2026}
}