Multi-Feature Fusion for RS Scenes
The model combines global context with fine-grained local features so that small structures and complex scene layouts are preserved.
Project Page
arXiv 2025
The model combines global context with fine-grained local features so that small structures and complex scene layouts are preserved.
Visual evidence is injected back into the language model during generation to reduce visual forgetting in long reasoning chains.
FUSE-RSVLM reports 65.76% VQA accuracy, 74.51% average classification accuracy, and state-of-the-art captioning results on multiple RS benchmarks.
Remote sensing imagery differs sharply from natural images: scenes are viewed from a nadir perspective, objects are small and dense, spatial layout is highly structured, and thin elements such as roads, bridges, ships, and vehicles can disappear after ordinary resizing. Existing remote sensing VLMs therefore face two coupled problems: they often fail to extract fine-grained local visual features, and they can suffer from visual forgetting as static visual tokens pass through deep language-centric decoding layers.
In this paper, we propose FUSE-RSVLM, whose core model is MF-RSVLM, a Multi-Feature Fusion Remote Sensing Vision-Language Model. The method learns multi-scale visual representations, combines global context with local details, and recurrently injects visual evidence into selected LLM layers. It is instruction-tuned with a 293K-sample remote-sensing instruction corpus covering captioning, VQA, visual grounding, scene classification, instruction QA, and detection.
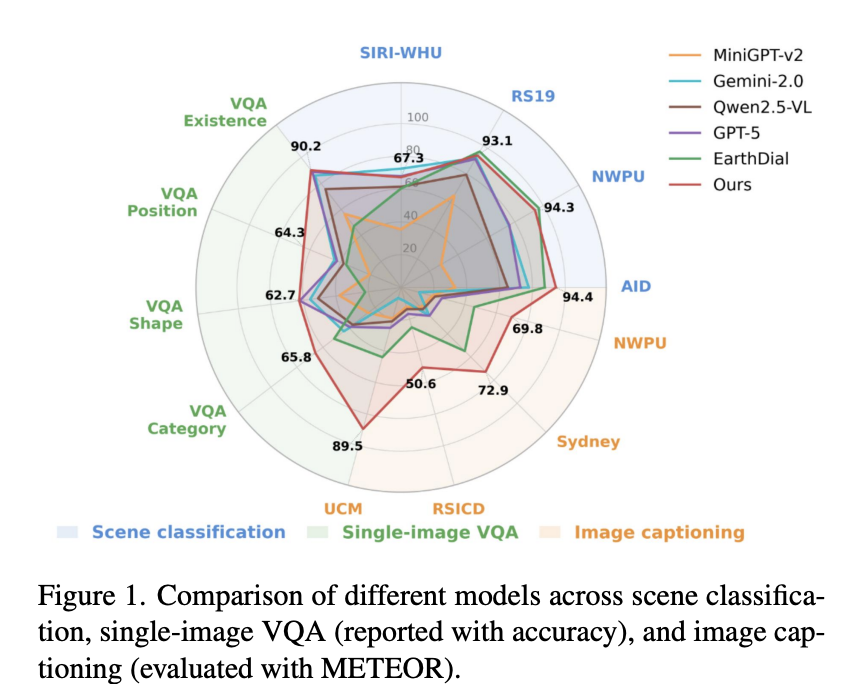
Task-Level Comparison. MF-RSVLM shows strong results across scene classification, single-image VQA, and image captioning, indicating that multi-feature fusion improves both perception and generation in remote-sensing scenes.
Remote Sensing Mismatch: Generic VLMs struggle with nadir-view imagery, tiny objects, dense layouts, and geospatial structures that are easily lost under fixed low-resolution encoding.
Multi-Scale Feature Extraction: MF-RSVLM combines low-resolution global tokens with high-resolution sliding-window detail stacks to preserve both holistic scene context and local evidence.
Recurrent Visual Injection: A router and gated injection module repeatedly writes relevant detail features into selected LLM layers, reducing visual forgetting during generation.
Strong Results: Experiments report 65.76% VRSBench VQA accuracy, 74.51% average classification accuracy, and state-of-the-art captioning on UCM-Captions and Sydney-Captions.
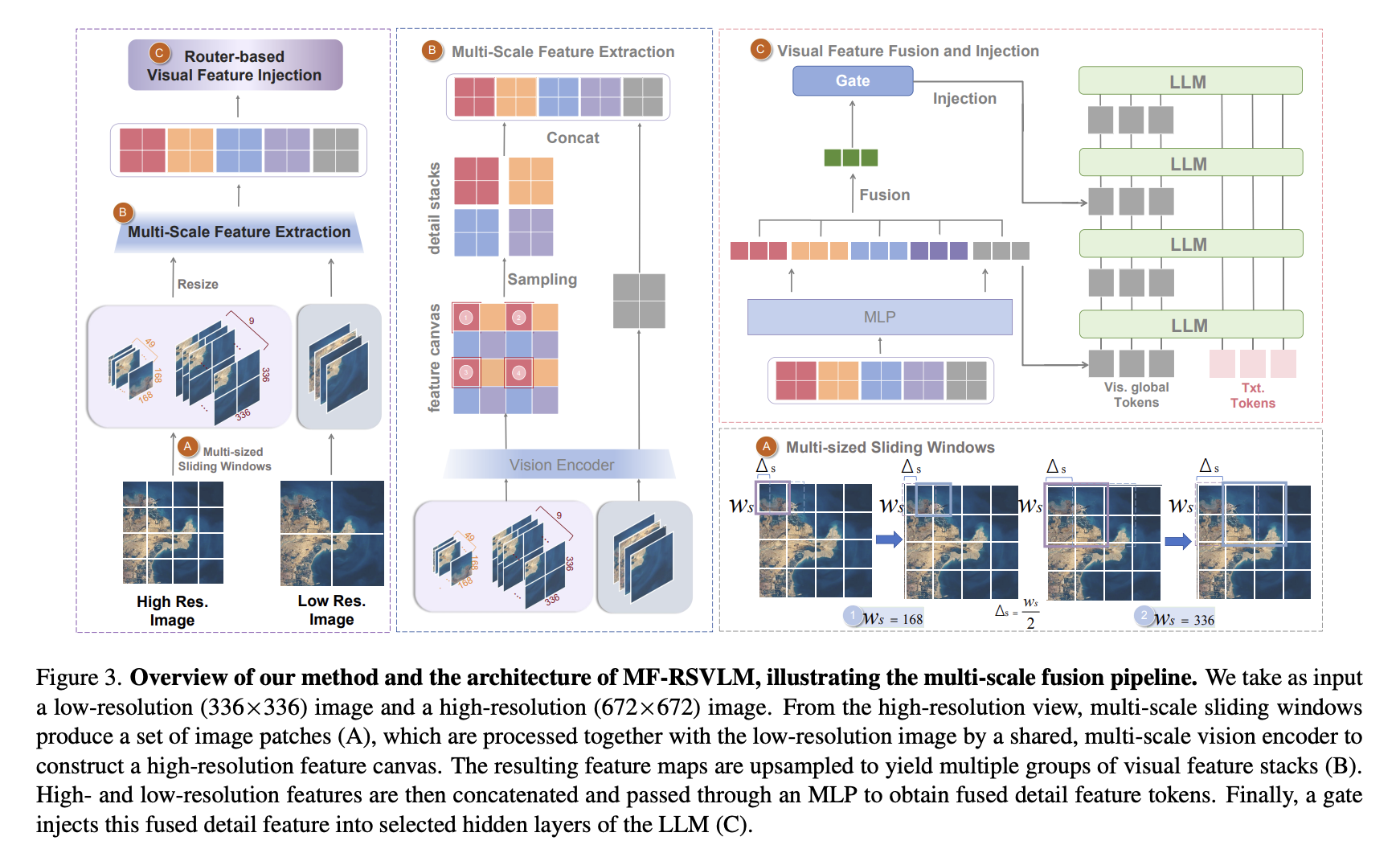
Method Overview. MF-RSVLM takes a low-resolution 336x336 image for global context and a high-resolution 672x672 image for local detail extraction. Multi-sized sliding windows generate local patches, the shared vision encoder builds a high-resolution feature canvas, and detail stacks are fused and injected into selected LLM layers through a gate.
The model follows a CLIP ViT-L/14@336 vision encoder, MLP projector, and Vicuna-v1.5-7B LLM pipeline. For global context, the image is resized to the ordinary low-resolution view and encoded into global visual tokens. For local detail, the image is resized to a 672x672 canvas, split into overlapping windows such as 336x336 and 168x168, and processed by the shared vision encoder. Features from ViT layers 8, 16, and 24 are scattered back onto a high-resolution feature canvas, then sampled into ordered detail stacks.
At LLM layers 2, 4, 6, and 8, a lightweight router selects relevant detail stacks conditioned on the current visual stream. A gate then controls how much of the fused detail is written back into the visual hidden states. This design keeps the representation visually grounded across decoding instead of relying on a one-time visual prefix.
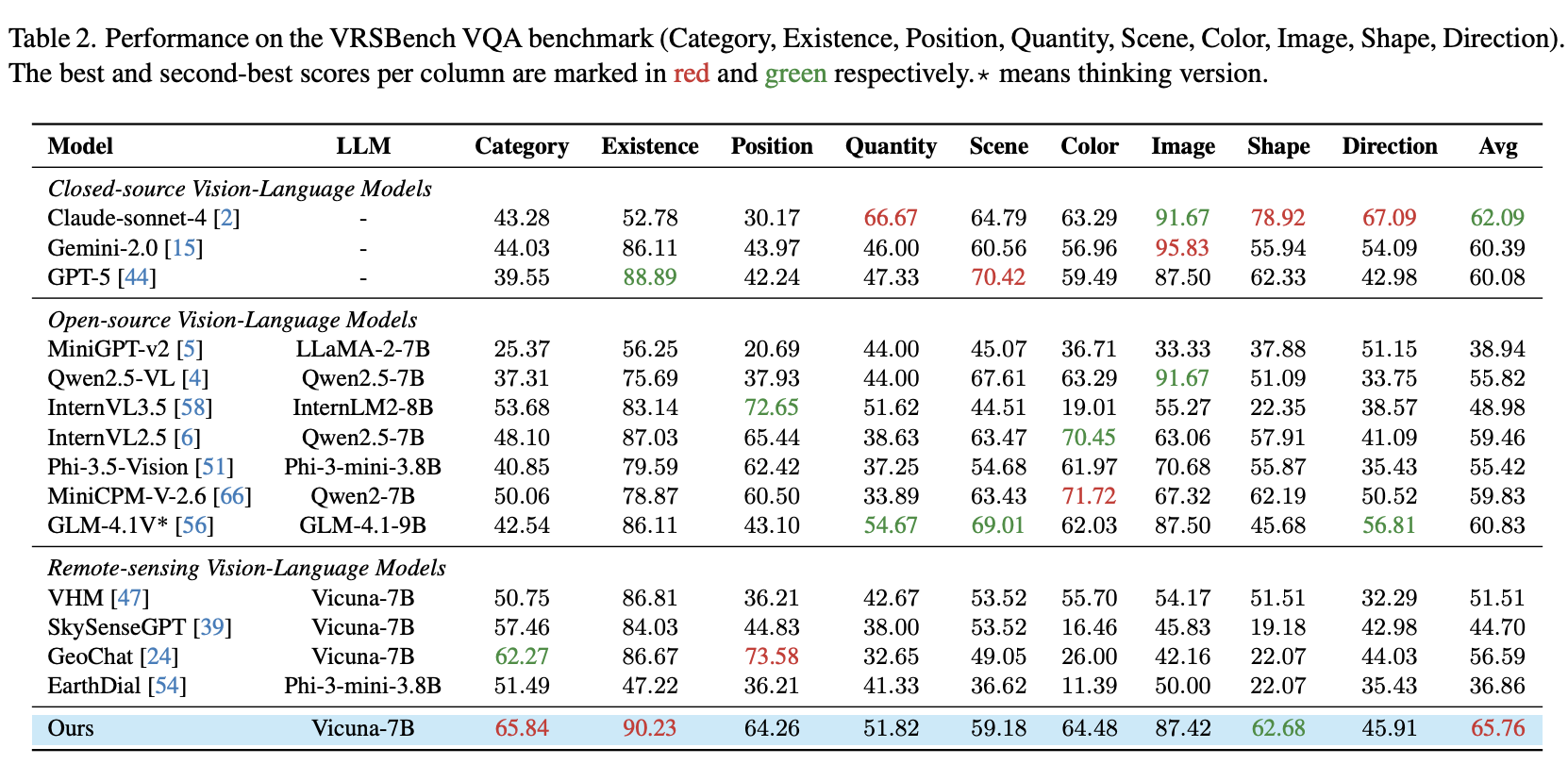
VRSBench VQA Results. MF-RSVLM ranks first overall with 65.76% average accuracy across Category, Existence, Position, Quantity, Scene, Color, Image, Shape, and Direction tasks.
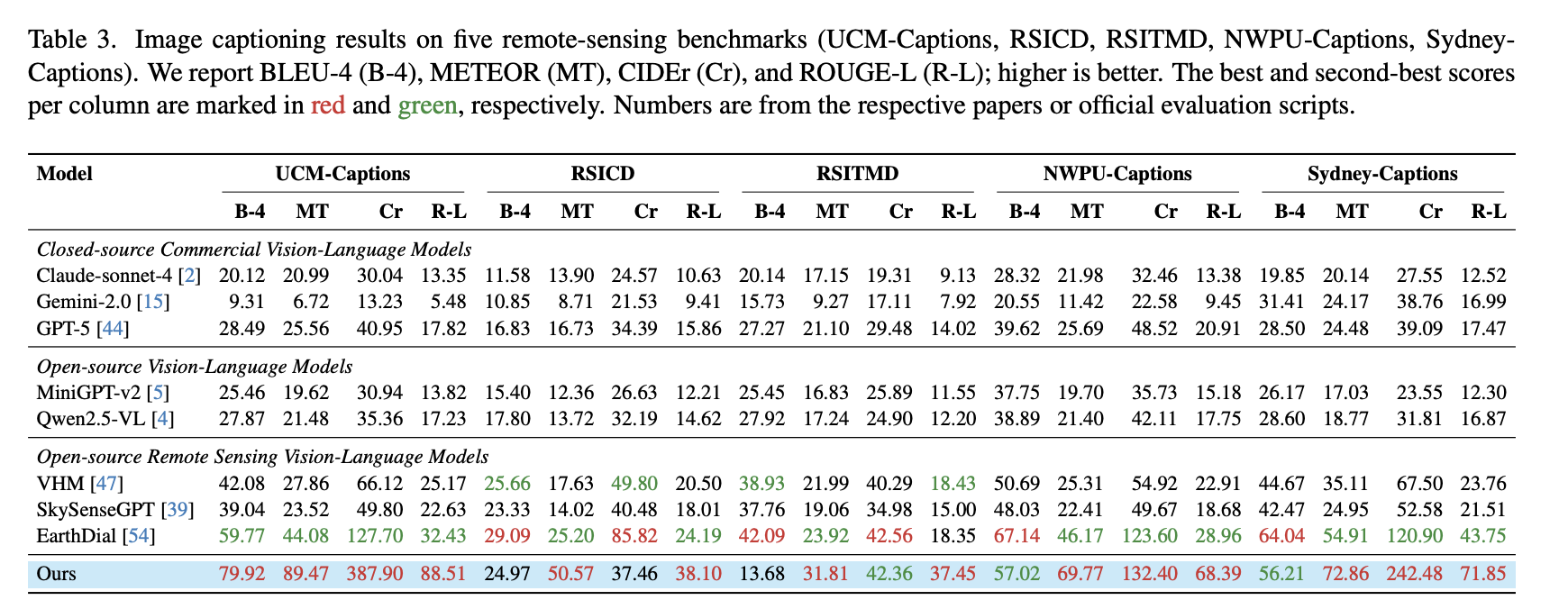
Image Captioning Results. Across five remote-sensing captioning benchmarks, MF-RSVLM reports new state-of-the-art results on UCM-Captions and Sydney-Captions and strong METEOR/ROUGE-L performance on the remaining datasets.

Qualitative Examples. Case studies on category, existence, and counting questions show that MF-RSVLM better preserves remote-sensing evidence needed for fine-grained answers.
The ablation studies support the design choices in the method. Fusing ViT layers 8/16/24 with both 336x336 and 168x168 sliding windows outperforms reduced layer or single-window variants across classification and composition benchmarks. Similarly, injecting visual features into LLM layers 2/4/6/8 gives the best overall result, improving METER-ML from 66.37% with fewer injection layers to 72.74%, and improving HR-Comp from 77.90% to 82.80%.
FUSE-RSVLM is not only another remote-sensing fine-tune. Its main value is that it treats visual grounding as a process that must be maintained through the whole reasoning chain. That is a better design for captioning, VQA, and classification in high-resolution geospatial imagery, where the decisive visual evidence may be small, sparse, or easily overwhelmed by global scene context.
The experimental results also show that remote-sensing-specific modeling choices still matter even in the era of general VLMs. Multi-scale visual fusion and recurrent detail injection remain strong advantages when the visual signal is dense, fine-grained, and spatially structured.
@article{dang2025fusersvlm,
title={FUSE-RSVLM: Feature Fusion Vision-Language Model for Remote Sensing},
author={Dang, Yunkai and Wang, Donghao and Yang, Jiacheng and Jiang, Yifan and Zhu, Meiyi and Yang, Yuekun and Wang, Cong and Fan, Qi and Li, Wenbin and Gao, Yang},
journal={arXiv preprint arXiv:2512.24022},
year={2025}
}