5,329 Ultra-High-Resolution Scenes
RSHR-Bench is built from full-scene remote sensing images with long sides of at least 4,000 pixels and much stricter visual requirements.
Project Page
arXiv 2025
RSHR-Bench is built from full-scene remote sensing images with long sides of at least 4,000 pixels and much stricter visual requirements.
The benchmark uses adversarial filtering and human verification to reduce shortcut answers that strong text-only LLMs can exploit.
It evaluates not only single-turn VQA but also captioning, open-ended reasoning, and multi-turn interaction in super-high-resolution settings.
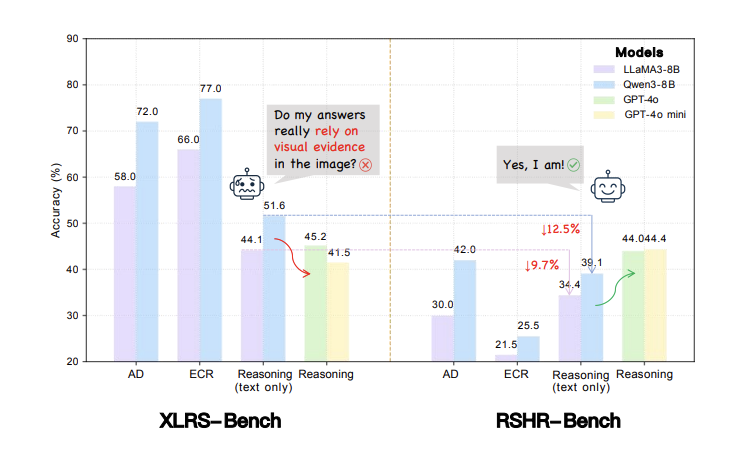
RSHR-Bench is built around a direct critique of current remote sensing multimodal evaluation: many benchmarks appear to test visual reasoning, but in practice a strong text-only LLM can sometimes answer a large fraction of the questions without seeing the image at all. That means benchmark scores can exaggerate visual understanding and understate the role of language priors.
The paper introduces a new benchmark for ultra-high-resolution remote sensing MLLMs where the images are large, the tasks are more interaction-heavy, and the annotation pipeline explicitly tries to reduce answer shortcuts. The benchmark is designed to test whether a model can connect high-resolution visual evidence to perception, reasoning, and multi-turn interaction.
RSHR-Bench contains 5,329 full-scene remote sensing images with a long side of at least 4,000 pixels, with some scenes reaching roughly 3 × 10^8 pixels. It includes 3,864 VQA tasks, 3,913 image captioning tasks, and 500 fully human-written or human-verified single-image evaluation pairs. The benchmark spans multiple-choice VQA, open-ended VQA, image captioning, and single-image evaluation, and covers nine perception categories together with four reasoning types.
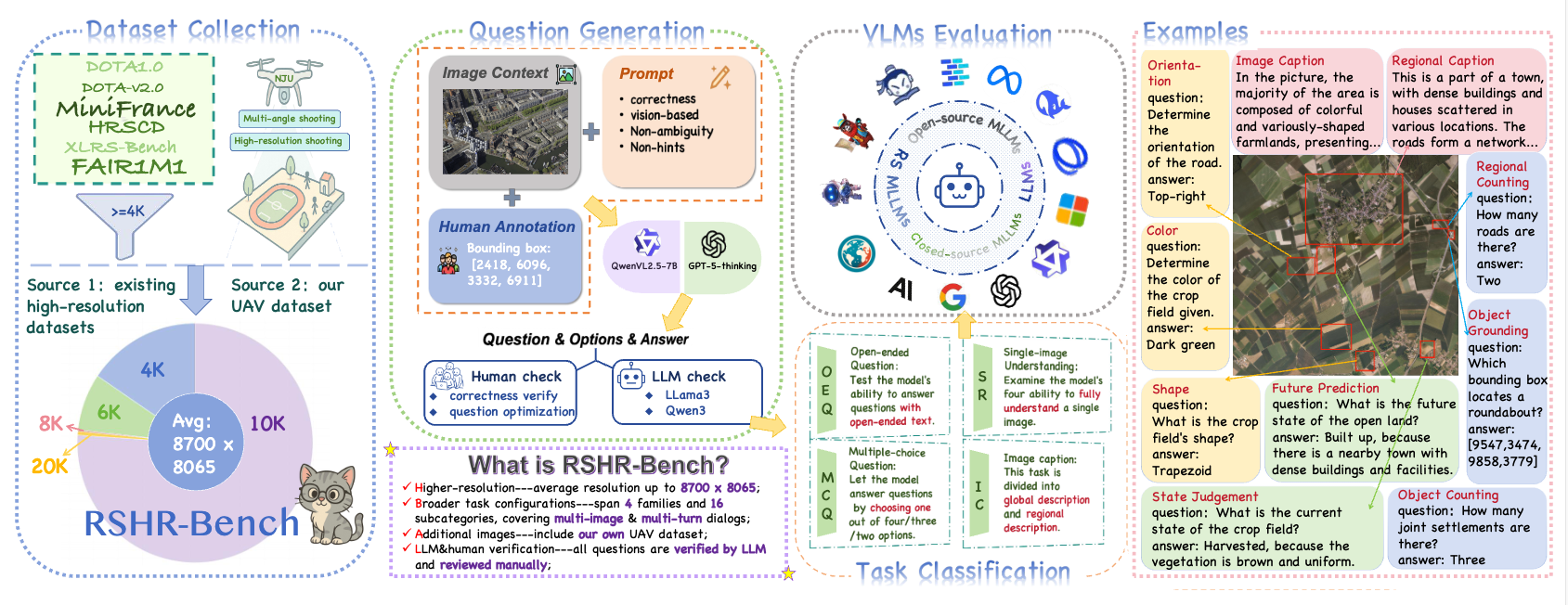
RSHR-Bench is designed to evaluate visual understanding on genuinely large remote sensing scenes rather than low-resolution shortcuts.
Motivation. Existing remote-sensing MLLM benchmarks can still allow answers driven by language priors, making stricter high-resolution visual grounding necessary.
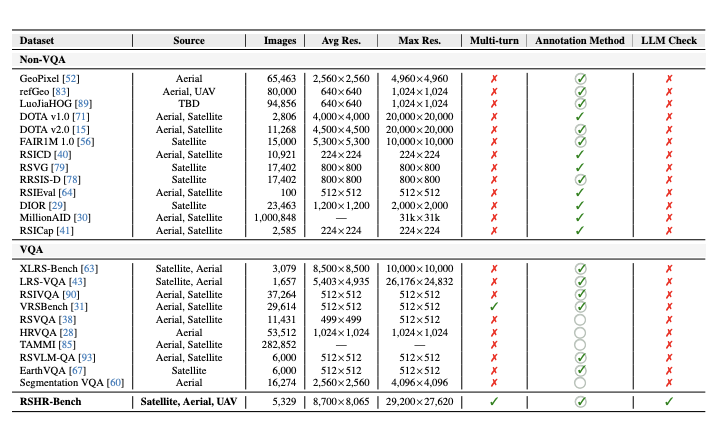
Benchmark Difference. RSHR-Bench emphasizes full-scene ultra-high-resolution imagery, richer interactions, and stronger filtering against shortcut reasoning.
Language-Prior Resistance: RSHR-Bench is explicitly designed to reduce shortcut answers that strong text-only models can exploit without seeing the image.
Ultra-High-Resolution Scale: the benchmark contains 5,329 full-scene images, with long sides of at least 4,000 pixels and scenes reaching roughly 3 × 10^8 pixels.
Task Diversity: it evaluates multiple-choice VQA, open-ended VQA, captioning, and single-image evaluation across perception, reasoning, and multi-turn interaction.
Key Finding: text-only models can still reach 51.6% reasoning accuracy on XLRS-Bench, showing why stricter visual evaluation is necessary.
Paper Resource: the benchmark design and evaluation details are available on arXiv.
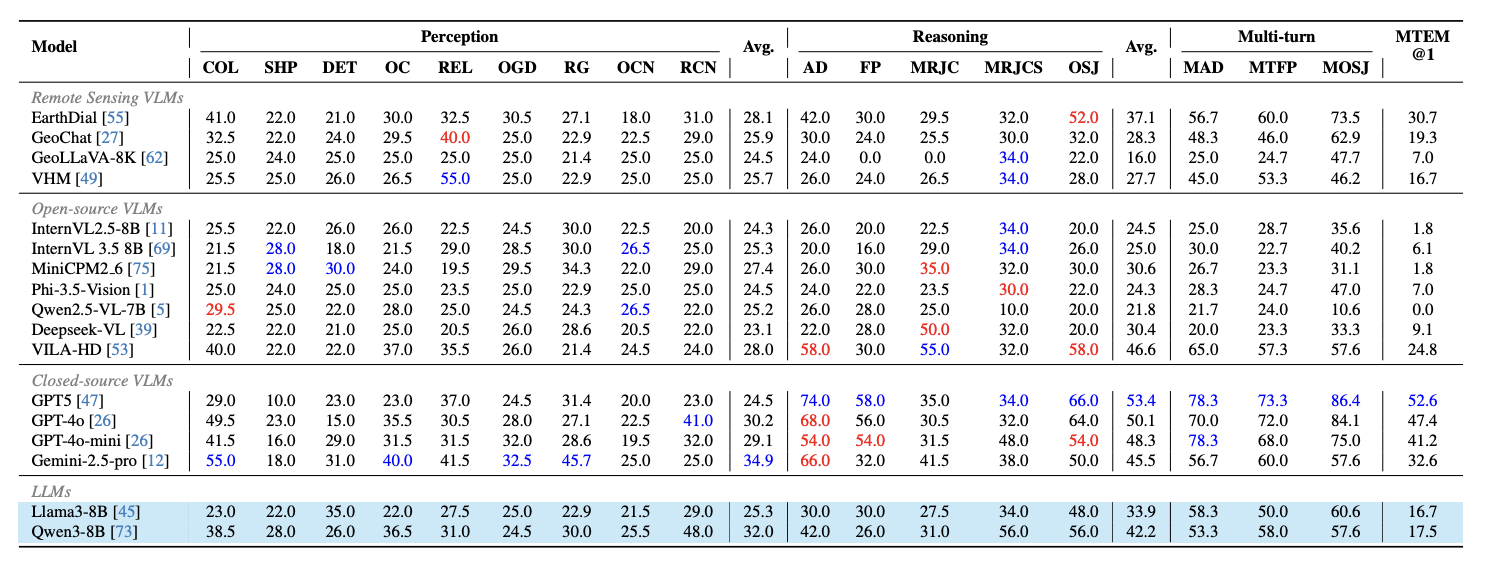
Experimental Results. The benchmark exposes clear gaps between text-prior behavior and grounded visual reasoning, especially on ultra-high-resolution remote-sensing tasks.
A useful benchmark should measure the capability we care about, not just the ability to exploit annotation artifacts. RSHR-Bench matters because it makes that distinction explicit. It is large enough, high-resolution enough, and carefully filtered enough to expose whether a model is actually using the image.
For future remote sensing MLLMs, this benchmark is valuable both as an evaluation tool and as a design pressure. It favors models that can preserve fine-grained visual grounding over long contexts and discourages systems that rely too heavily on language priors.
@article{dang2025RSHR,
title={A Benchmark for Ultra-High-Resolution Remote Sensing MLLMs},
author={Dang, Yunkai and Zhu, Meiyi and Wang, Donghao and Zhang, Yizhuo and Yang, Jiacheng and Fan, Qi and Yang, Yuekun and Li, Wenbin and Miao, Feng and Gao, Yang},
journal={arXiv preprint arXiv:2512.17319},
year={2025}
}