Structured Map Of MLLM Explainability
The survey organizes methods, benchmarks, and applications into a coherent landscape instead of a loose paper list.
Project Page
arXiv 2024
The survey organizes methods, benchmarks, and applications into a coherent landscape instead of a loose paper list.
It frames interpretability from the viewpoints of data, model internals, and training or inference behavior.
The paper highlights that faithful, useful, and robust explanation evaluation remains a major open problem.
This survey addresses a problem that becomes more urgent as multimodal large language models become more capable: their decisions are harder to inspect, debug, and justify. MLLMs can already solve a wide range of tasks across image-text generation, visual question answering, retrieval, and multimodal reasoning, but the mechanisms behind those outputs often remain opaque. The survey is motivated by the view that performance alone is not enough; interpretability and explainability are necessary if these systems are to be trusted in high-stakes settings.
Rather than listing papers loosely, the survey builds a structured map of the field. It covers explainability methods, benchmark design, evaluation protocols, and open challenges across model architectures, training procedures, and inference strategies.
The paper organizes the literature from three main perspectives: data, model, and training or inference. It also examines interpretability at multiple granularities, from token-level interactions to embedding-level representations and higher-level module behavior. In addition to analysis tools, the survey covers architecture design choices, alignment methods, hallucination-oriented explanation work, robustness benchmarks, and application-specific interpretability studies.
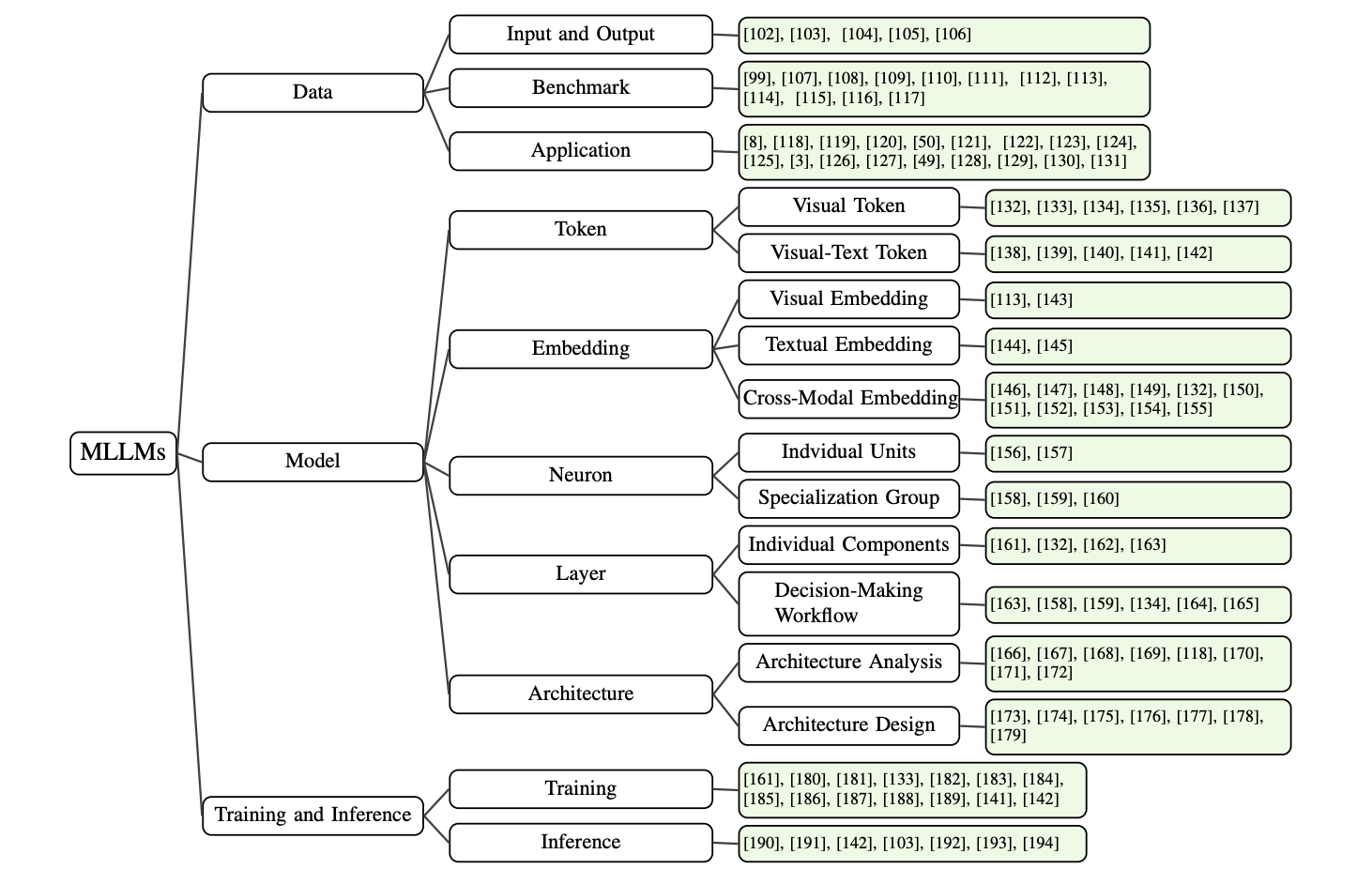
The survey organizes MLLM explainability research across data, model, and training or inference dimensions, while also covering benchmarks and applications.
Explainability Challenge: as multimodal large language models become more capable, their decisions become harder to inspect, debug, and justify.
Three-Perspective Framework: the survey organizes the literature from the viewpoints of data, model, and training or inference.
Evaluation Gap: the paper emphasizes that the field still lacks strong standards for measuring whether an explanation is faithful, useful, and robust.
Survey Value: this work acts as infrastructure for the area by giving researchers a structured map of methods, benchmarks, and open problems.
Paper Resource: the full survey is available on arXiv.
This is not a paper list dressed up as a survey. Its main value is that it gives the field a common explanatory framework for understanding where interpretability tools work, where they fail, and where evaluation is still too weak.
This paper is valuable less as a single algorithm and more as infrastructure for the research area. It gives researchers a common vocabulary for discussing explainability in MLLMs and helps separate what is already mature from what is still poorly understood.
For practitioners, the survey is useful because it makes clear that transparency is not one technique but a stack of decisions: dataset design, representation learning, model architecture, alignment, decoding, and post-hoc analysis all interact. If the goal is more accountable multimodal AI, this survey is a strong starting point.
@article{dang2024explainable,
title={Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey},
author={Dang, Yunkai and Huang, Kaichen and Huo, Jiahao and Yan, Yibo and Huang, Sirui and Liu, Dongrui and Gao, Mengxi and Zhang, Jie and Qian, Chen and Wang, Kun and Liu, Yong and Shao, Jing and Xiong, Hui and Hu, Xuming},
journal={arXiv preprint arXiv:2412.02104},
year={2024}
}